



Mr. Edward Bear (pseudonym) shared an awesome secret for sussing out quote issues in a previous post. He’s back with a nifty way to help spot spelling issues. It helped me spot a number of inconsistencies in Bad Penny, which I recently fixed. Take it away, Mr. Bear.
* * * *
Augmented Proofreading 2
Last time, I mentioned checking spelling and spelling consistency, and this note is to fulfill my promise.
To begin with, I’ll admit freely I do not recommend just running a spieling chucker over the text. And yes, I’m using the phrase deliberately. The spelling checker in the program I’m using to write this just waltzed right past it, despite the fact that neither word makes sense in this context. I got started trying to get some mileage out of spelling checkers a while back, when I realized that OCR scanners will work like hell trying to find a word and probably will come up with a word, but it will be the wrong word. Over at Project Gutenberg, they use the term “scanos” as an analogue of “typos.”
The other adversary is consistency of spelling and usage. Examples might include “canceled” and “cancelled” or variant possessives, such as “Jones’” and “Jones’s” in the same text, or simply variant spellings of the same character’s name, such as “Erik” and “Eric.”
So what do I do for these sorts of problems?
What you need is a list of all the unique words in the story, and it’s easy with a dollop of regex. (See the first post on this topic. The one I’ve taken to using is the following:
[^-‘‘’\w\d\r\n]
This one I can explain, since I wrote it. 🙂
What it says is to look for any individual characters within the brackets([]). The leading caret (^) says “Nope, they should not be in this list.” Following that are the hyphen(-), the straight quote(‘), and the opening and closing curly single quotes(‘’). After that, it’s any character that would normally be in a word (\w), any digit (\d), any carriage return(\r) or any new line aka paragraph terminator (\n).
And what you do with the above is to set Textpad (see previous post again) to replace all of them with a newline (\n) character.
Here’s what the search and replace box in Textpad looks like for this:
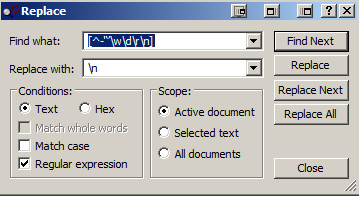
Notice that the “Regular expression” box is checked. And then you choose “Replace All”.
The result is to turn this:
Once upon a night we’ll wake to the carnival of life
The beauty of this ride ahead such an incredible high
It’s hard to light a candle, easy to curse the dark instead
This moment the dawn of humanity
The last ride of the day
into this:
Once
upon
a
night
we’ll
wake
to
the
carnival
of
life
The
beauty
of
this
ride
ahead
such
an
incredible
high
It’s
hard
to
light
a
candle
easy
to
curse
the
dark
instead
This
moment
the
dawn
of
humanity
The
last
ride
of
the
day
For a book, this means what you have as a multi-thousand line long document and LOTS of repeated words. The next step is to lose the repetitions by sorting the list. For TextPad, you’ll find Tools->Sort on the menu bar, and I generally set the sort up as the following:
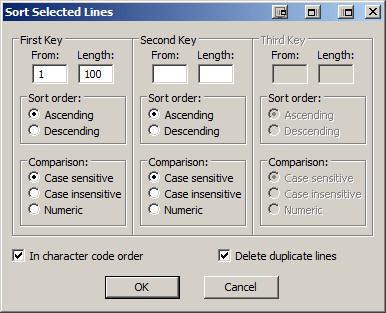
This is a case-sensitive sort and “Delete duplicate lines”, of course, gets rid of all the duplications of words like “a”, “an”, and “the”.
For the above text, you get:
It’s
Once
The
This
a
ahead
an
beauty
candle
carnival
curse
dark
dawn
day
easy
hard
high
humanity
incredible
instead
last
life
light
moment
night
of
ride
such
the
this
to
upon
wake
we’ll
34 unique words.
And here’s the payoff for all this funky text munging: Run a spelling checker over this, and it will find typos, of course, but it will also generally complain about most names, which aren’t generally kept in spelling checker dictionaries, and it will also show you words and their variants, nestled fairly closely together. Here’s an example from one of my projects:
Swiss-born
Take
Talking
Tallmadge
Tallmadge’s
Tarelton
Tarleton
Tarleton’s
Tavern
Tecumseh
Tell
Ten
Thames
The spelling checker landed on Tallmadge and its possessive form, but do you notice the “Tarelton” on the list? That’s the time for the Aha!, and you can fix the “Tarelton” form. The same thing applies to possessive variants and any other variant form you find.
As with the last post, I’ll be peeking in on the comments and answering any questions that come up.












Why do you include an opening curly single quote: ‘ ? Is that in case it is incorrectly used as an apostrophe? It seems like your list could end up with unnecessary duplicate copies of words that start a single-quote (one with the attached opening curly single quote, and one without the quote).
@Johnw I include the opening curly single quote because it will help me catch contracted words like ’em which frequently get mangled into ‘em by assumptions built into Word or typesetting software which sets ’em up that way. It gives me a quick index of such words and makes ’em easy to find and double-check. Admittedly, quotes inside dialogue, which are surrounded, will generate words such as ‘lucky from ‘lucky is he who has friends’, but contracted words still stand out.
The whole point of this sort of thing is to call the user’s attention to likely candidates which need double-checked.
These days, when I get an assignment, the typesetter sends me both an RTF or DOCX of the text, and a searchable PDF, to go with the paper copy. So this afternoon, when I got to that stage on my latest project, it took me maybe ten minutes to find ALL occurrences of ‘em and ‘bot and get them marked on the print copy and added to the log for correction.
One other note. I entered the single quotes in my prior post as curly quotes, but the website software made them straight ones. :dang: